Prob model problem
Compute the probability of the tag sequence DT NN
in Brown.
Compute the probability of 'walked' given 'VBD' in Brown.
HMM Tagging Problem: Part I
Complexity issues have reared their ugly
heads again and with the IPO date on your
new comp ling startup fast approaching,
you have discovered that if your hot
new system is going
to parse sentences as long
as 4 words,
you had better
limit yourself to a
3-word vocabulary.
Consider the following HMM
tagger for tagging texts constructed with
a 3 word vocabulary.
- station
- ground
- control
and a tagset of 2 tags:
- V [Verb]
- N [Noun]
Our HMM tagger always starts in the Start state,
and always ends in the End state,
You can use this tagger to assign
the most likely tag sequence
to any sequence
of words taken from our small vocabulary.
Consider the following input to
our tagger:
There are 4 different state sequences
that will accept this input:
- Start V V end
- Start V N end
- Start N N end
- Start N V end
These correspond to 4 different
assignments of part-of-speech
tags to
the two input words (ground ground).
Here is the entire probability model:
-
|
|
Pr(wi | ti)
|
|
w
|
Pr(w | N )
|
Pr(w | V )
|
Pr(w | Start )
|
Pr(w | End )
|
|
ground
|
.4
|
.3
|
0
|
0
|
|
control
|
.3
|
.3
|
0
|
0
|
|
station
|
.3
|
.4
|
0
|
0
|
|
Λ
|
0
|
0
|
1.0
|
1.0
|
-
|
Pr(ti | ti-1)
|
|
N
|
V
|
Start
|
End
|
Pr(V | N)
.5
|
Pr(V | V)
.1
|
Pr(V | Start)
.5
|
Pr(End | V)
.5
|
Pr(N | N)
.5
|
Pr(N | V)
.9
|
Pr(N | Start)
.5
|
Pr(End | N)
.5
|
Now let's apply the prob model to an example.
| | ground | |
ground |
| start | V | |
N | end |
| |
.3 * .5 * | |
.4 * .9 * |
.5 |
So this corresponds to the path
in which the first occurrence of
ground is labeled a verb,
and the second a noun.
Let's review where these transition probabilities come from.
The probability model being used is the following.
Prob(w1,n,t1,n)= Pii=1
P(wi | t i) * P(ti | t i-1)
That is, the joint probability of a word sequence
n words long and a tag
sequence n + 1 tags long is equal to the product of
the probabilities of each word given its
tag times the probability of each
tag given the previous tag. There is one extra
tag because we take the tag at t=0
to be start. For each wi,
then, we get a factor:
|
P(wi | t i) | * | P(ti | t i-1) |
For our example, according to this probability model
we calculate the joint probability to be:
.3 * .5 * .4 * .9 * .5 = .027
This is the product of the transition probabilities
for this path through the HMM.
There are three others.
To find the most likely assignment of
tags we need to find the most
probable path through the HMM.
This is what the Viterbi algorithm is for.
Problem 3 Proper
Tag the following input:
This can be done by computing the products
of the transition probabilities (called the
path probabilities) for all 16 paths
through the HMM and choosing the most
probable path.
But the assigned problem is to choose
the most probable path by using the Viterbi
algorithm.
To help you
get started, here is the partial Viterbi matrix for our HMM and
the given input:
|
End
|
0
|
|
|
|
|
|
V
|
0
|
|
|
|
|
|
N
|
0
|
|
|
|
|
|
Start
|
1.0
|
|
|
|
|
|
|
Λ
|
ground
|
control
|
station
|
Λ
|
|
t=0
|
t=1
|
t=2
|
t=3
|
t=4
|
Note that the Viterbi values for t=0
have already been filled in. Continue the matrix
and fill in the values for t=1, t=2, t=3,
and t=4. Show your calculations.
Use the following figure from the book to
guide your notation:
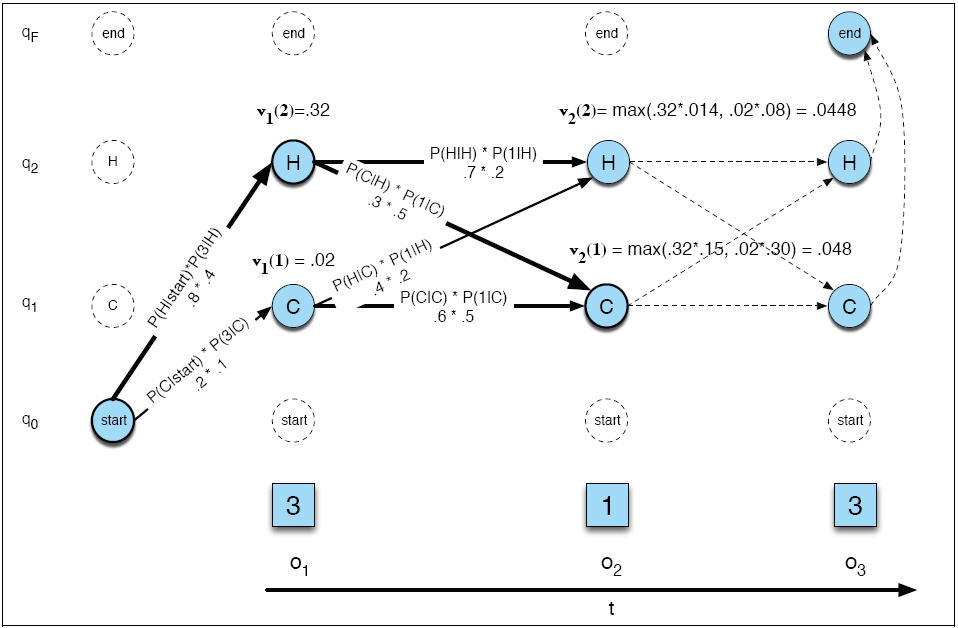
You are filling the table with v values,
shown as v1, v2. v1(2) repesents the probability of
the best path ending at state 2 at time 1. It
is computed as a max of 2 path probabilitoes.
Each of those path probabilities is
computed from two components. Take for example
the path from state H ending at state H at t=2.
First there is the cost of getting from
H to H. That is, P(H|H) * P(1|H), the product of the transition
and observation probabilities (=0.14). Then
there is V1(2) (=.32). The product of these two components
is .32 * .014. So that covers the cost of the best path
passing through H2 at t=1 and ending at H2 at t=2.
We also need to consider the ossibilitiy
of passing through H1 at t=1 and ending at H2 at t=2
(also shown). That gives us two **path probabilities**.
We take the max of those to get v2(2).
Part C
Using the results of your Viterbi calculation,
give the most probable state sequence
through the HMM: